
In unserem letzten Artikel haben wir die Herausforderungen von einfachen oder naiven Retrieval-Augmented Generation (RAG)-Systemen aufgezeigt, insbesondere im Kontext von Unternehmensanwendungen. Wir haben Probleme wie Abrufschwierigkeiten aufgrund semantischer Mehrdeutigkeit und den Mangel an Tiefe und Kohärenz in den generierten Antworten festgestellt. Diese Erkenntnisse machten deutlich, dass die grundlegenden RAG-Systeme zwar einen bedeutenden Fortschritt in der KI darstellen, aber nicht frei von Einschränkungen sind. Die Anerkennung dieser Herausforderungen hat den Weg für weiterentwickelte und nuancierte Ansätze in den Phasen der Retrieval-Augmented Generation geebnet. Heute stehen wir an der Schwelle zu einer neuen Ära der KI und Informationsverarbeitung, in der Advanced RAG Systems nicht nur inkrementelle Verbesserungen, sondern transformative Lösungen bieten. Diese Systeme zeigen, wie LLMs effektiv mit geerdeten, aktuellen und internen Datenquellen gekoppelt werden können. Diese Integration passt ihre Fähigkeiten an die spezifischen Anforderungen von Unternehmensanwendungen an und geht von den Unzulänglichkeiten einfacher RAG-Systeme zu einer ausgefeilten Architektur über, die eine kontextbezogene, genaue und relevante KI-Lösung in komplexen Geschäftsumgebungen bietet. In diesem Artikel erfahren wir mehr über die ausgeklügelte Architektur der fortschrittlichen RAG-Systeme, die die Unzulänglichkeiten ihrer Vorgänger überwinden sollen. Wir wollen ihre Kernkomponenten aufschlüsseln und zeigen, wie sie reale Unternehmensszenarien meistern. Als Vorläufer einer umfassenden technischen Serie werden wir die einzelnen Aspekte dieser Systeme näher beleuchten und denjenigen, die sich in der sich entwickelnden KI-Landschaft bewegen, praktische Einblicke geben. Mach mit bei dieser Serie, in der wir das Potenzial von Advanced RAG Systems aufdecken, die Praktiken der Industrie zu revolutionieren und die Möglichkeiten der generativen KI zu erweitern.
Der Bedarf an fortschrittlichen Retrieval-Augmented Generation (RAG)-Systemen

Herausforderungen, die von grundlegenden RAG-Systemen bewältigt werden
Die Einführung grundlegender RAG-Systeme war ein bedeutender Schritt zur Überwindung der Herausforderungen, mit denen eigenständige generative Modelle konfrontiert sind:
- Halluzinationen bei Antworten: Diese Modelle erzeugten oft faktisch falsche oder „halluzinierte“ Inhalte, die nicht anhand zuverlässiger Datenquellen überprüft werden konnten.
- Begrenzte Wissensbasis: Sie waren durch das bei ihrer letzten Ausbildung vorhandene Wissen eingeschränkt, was ihre Fähigkeit, aktuelle oder bereichsspezifische Informationen zu geben, behindert hat.
- Kosten für Schulungen und Aktualisierungen: Die kontinuierliche Schulung und Aktualisierung der LLMs zur Aufnahme neuer Informationen war ressourcenintensiv und kostspielig und stellte eine Herausforderung für die Aufrechterhaltung der Leistung auf dem neuesten Stand dar.
Grundlegende RAG-Systeme zielten darauf ab, diese Probleme zu entschärfen, indem sie generative Modelle mit Echtzeit-Datenabfragen ergänzten und so die Genauigkeit und Relevanz der Antworten verbesserten.
Der Übergang zu fortschrittlichen RAG-Systemen für komplexe Bedürfnisse
Trotz ihres innovativen Ansatzes stoßen die grundlegenden RAG-Systeme an ihre Grenzen, insbesondere in differenzierten Unternehmensszenarien:
- Probleme beim Abrufen von Daten: Aufgrund von semantischer Mehrdeutigkeit und unzureichender Granularität hatten sie Schwierigkeiten, die Daten korrekt abzurufen.
- Herausforderungen bei der Erweiterung: Schwierigkeiten bei der Integration von Kontext und der Priorisierung von Informationen führten zu unzusammenhängenden oder oberflächlichen Inhalten.
- Defizite der Generation: Die Antworten waren oft nicht kohärent, konsistent und tiefgründig genug und wurden den komplexen Anforderungen des Unternehmens nicht gerecht.
Diese Einschränkungen unterstrichen den Bedarf an ausgefeilteren Lösungen. Hier kommen die modernen RAG-Systeme ins Spiel, die speziell für diese komplexen Herausforderungen entwickelt wurden.
Erkenntnisse aus einer aktuellen Studie über Fehlerpunkte von RAG-Systemen
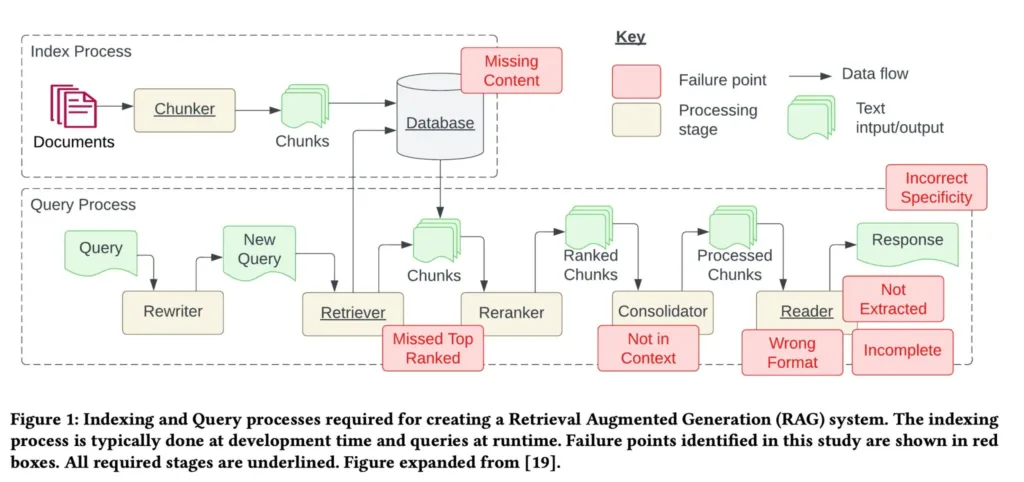 Eine aktuelle Studie mit dem Titel „Seven Failure Points When Engineering a Retrieval Augmented Generation System“ (Sieben Fehlerpunkte bei der Entwicklung eines Retrieval Augmented Generation Systems) versucht, unser Verständnis für die Feinheiten von RAG-Systemen zu verbessern. Es werden sieben zentrale Fehlerpunkte identifiziert, die jeweils bestimmte Bereiche aufzeigen, in denen RAG-Systeme möglicherweise keine optimalen Ergebnisse liefern. Diese Fehlerpunkte sind:
Eine aktuelle Studie mit dem Titel „Seven Failure Points When Engineering a Retrieval Augmented Generation System“ (Sieben Fehlerpunkte bei der Entwicklung eines Retrieval Augmented Generation Systems) versucht, unser Verständnis für die Feinheiten von RAG-Systemen zu verbessern. Es werden sieben zentrale Fehlerpunkte identifiziert, die jeweils bestimmte Bereiche aufzeigen, in denen RAG-Systeme möglicherweise keine optimalen Ergebnisse liefern. Diese Fehlerpunkte sind:
- Fehlende Inhalte (FP1): Fragen ohne klare Antworten können zu irreführenden Antworten führen.
- Die bestplatzierten Dokumente wurden verpasst (FP2): Relevante Dokumente sind möglicherweise nicht hoch genug eingestuft, um in den Nutzerergebnissen enthalten zu sein.
- Nicht im Kontext – Einschränkungen der Konsolidierungsstrategie (FP3): Das Abrufen von Antworten wird bei einer großen Anzahl von Dokumenten erschwert.
- Nicht extrahiert (FP4): Rauschen oder widersprüchliche Daten können dazu führen, dass die richtigen Informationen nicht extrahiert werden.
- Falsches Format (FP5): Das System missachtet möglicherweise bestimmte Anweisungen für die Extraktion von Informationen in einem bestimmten Format.
- Falsche Spezifität (FP6): Die Antworten sind entweder nicht spezifisch genug oder übermäßig spezifisch.
- Unvollständig (FP7): In den Antworten können wichtige Details fehlen, was zu unvollständigen Antworten führt.
Bei der Erforschung fortschrittlicher RAG-Systeme ist es wichtig, die Erkenntnisse aus unseren früheren Diskussionen mit den in der aktuellen Studie identifizierten Fehlerpunkten zu verknüpfen . Diese Verbindung bietet eine umfassende Perspektive auf die anstehenden Herausforderungen und ebnet den Weg für die Lösungen, die die fortschrittlichen RAG-Systeme bieten. Im Folgenden werden unsere bisherigen Erkenntnisse mit den in der Studie identifizierten Schwachstellen abgeglichen:
- Abrufphase:
- Die Punkte „Verwirrende Bedeutungen“ und „Falsche Kriterienzuordnung“ aus unserem vorherigen Artikel stimmen mit den Fehlerpunkten 1 (fehlender Inhalt) und 2 (fehlende Top-Ranked-Dokumente) überein. Diese Parallelen verdeutlichen die Schwierigkeiten bei der genauen Datenabfrage und der Relevanz der Antworten.
- Erweiterungsphase:
- Themen wie „Kontextintegration“ und „Redundanz“ entsprechen den Fehlerpunkten 3 (nicht im Kontext) und 4 (nicht extrahiert) und verdeutlichen die Komplexität der Synthese von Informationen aus mehreren Dokumenten und die Verwaltung widersprüchlicher Daten.
- Generation Stage:
- Die Punkte „Kohärenz und Konsistenz“ und „Übergeneralisierung“ spiegeln die Bedenken der Fehlerpunkte 1, 6 (falsche Spezifität) und 7 (unvollständig) wider und unterstreichen die Notwendigkeit von kontextuell vollständigen und spezifischen Antworten.
Indem wir diese Aspekte abbilden, erkennen wir die breiteren Muster der Herausforderungen bei der Informationsbeschaffung und -verarbeitung. Fortgeschrittene RAG-Systeme sollen nicht nur einzelne Probleme angehen, sondern ganzheitliche Lösungen bieten, die den gesamten Prozess des Abrufens, Erweiterns und Erzeugens verbessern. Die Verknüpfung früherer Erkenntnisse mit fortschrittlichen RAG-Systemen Die Synthese unserer früheren Analysen und die Ergebnisse der jüngsten Studien bilden die Grundlage für unsere Erkundung fortschrittlicher RAG-Systeme. Diese Systeme werden sorgfältig entwickelt, um bestimmte Bedürfnisse zu erfüllen:
- Verbesserung der Genauigkeit der Datenabfrage und des kontextuellen Verständnisses: Sie zielen darauf ab, die Genauigkeit der Datenabfrage zu verbessern und das kontextuelle Verständnis der verarbeiteten Informationen zu vertiefen.
- Verbesserte Informationsintegration und -synthese: Diese Systeme sind so konzipiert, dass sie Informationen aus einer Vielzahl von Quellen effektiv zusammenführen und synthetisieren, um einen nahtlosen Integrationsprozess zu gewährleisten.
- Bieten kohärentere und kontextreichere Generierungsmöglichkeiten: Fortschrittliche RAG-Systeme sind bestrebt, Antworten zu generieren, die nicht nur kohärent, sondern auch kontextreich sind und somit aufschlussreiche und relevante Ergebnisse liefern.
Vorschau auf die fortgeschrittene RAG-Systemarchitektur In den nächsten Abschnitten werden wir uns mit den architektonischen Feinheiten fortgeschrittener RAG-Systeme beschäftigen. Unsere Reise wird uns durch die wesentlichen Komponenten führen, von der Datenaufbereitung bis hin zu den Feinheiten der Informationsgenerierung. Wir zeigen, wie jede einzelne Komponente eine zentrale Rolle bei der Entwicklung eines robusten, präzisen und effizienten KI-Tools für anspruchsvolle Unternehmensanwendungen spielt. Während wir diese Elemente erforschen, werden wir entdecken, wie diese fortschrittlichen KI-Lösungen an die individuellen Geschäftsanforderungen angepasst werden können und so neue Wege für Innovationen und die Verbesserung der Wettbewerbsfähigkeit eröffnen.
Fortgeschrittene RAG-Systeme: Die Unzulänglichkeiten der naiven RAG

Der Übergang von einfachen zu fortgeschrittenen Retrieval-Augmented Generation (RAG)-Systemen ist ein entscheidender Fortschritt in der KI, der speziell darauf zugeschnitten ist, die Unzulänglichkeiten naiver RAG-Systeme zu beheben. Fortschrittliche RAG-Architekturen integrieren innovative Lösungen, die sich eng an den Bedürfnissen komplexer Unternehmensanwendungen orientieren. Sehen wir uns an, wie diese fortschrittlichen Systeme die kritischen Fehlerpunkte angehen, die in früheren Modellen und Studien identifiziert wurden: 1. Verbessertes Chunking und Vektorisierung (FP1 – fehlender Inhalt und FP4 – nicht extrahiert):
- Effizientes Chunking: Fortschrittliche RAG-Systeme setzen intelligentes Chunking ein, das große Dokumente in kleinere, semantisch sinnvolle Einheiten zerlegt. Das sorgt für eine bessere Darstellung der Inhalte und macht es dem System leichter, relevante Informationen abzurufen und zu verarbeiten.
- Hochentwickelte Vektorisierung: Durch den Einsatz modernster Einbettungsmodelle verbessern diese Systeme ihre Fähigkeit, Textabschnitte genau zu vektorisieren. Dies führt zu einem präziseren semantischen Abgleich zwischen Abfragen und Dokumenteninhalten und löst Probleme im Zusammenhang mit der Extraktion von Inhalten und fehlenden Informationen.
2. Verbesserter Suchindex (Behebung von FP2 – verpasste Top-Ranked-Dokumente und FP3 – nicht im Kontext):
- Vektorspeicher-Index: Moderne RAG-Systeme verwenden optimierte Vektorindizes wie faiss oder annoy, die eine effiziente und genaue Suche in umfangreichen Datensätzen ermöglichen.
- Hierarchische Indizes: Die Implementierung einer zweistufigen Indexierungsstrategie, bei der Zusammenfassungen die erste Dokumentenauswahl leiten, gefolgt von einer detaillierten Suche nach Chunks, gewährleistet kontextbezogene und umfassende Suchergebnisse.
3. Hypothetische Fragen und HyDE (Verbesserung von FP2 und FP3):
- Hypothetische Fragen einbetten: Bei diesem neuartigen Ansatz werden für jedes Textstück hypothetische Fragen erstellt und für die Suche eingebettet. Sie verbessert die semantische Suche, indem sie die Suchanfragen eng mit den möglichen Antworten abgleicht und so die kontextuelle Relevanz der abgerufenen Dokumente erhöht.
- Hypothetische Dokumenteneinbettung (HyDE): Auch diese Systeme generieren hypothetische Antworten auf der Grundlage von Nutzeranfragen. Dieser Ansatz verbessert den semantischen Abgleich beim Retrievalprozess, indem er Probleme im Zusammenhang mit der Kontextrelevanz und fehlenden hochrangigen Dokumenten effektiv angeht.
4. Strategien zur Kontextanreicherung (Verfeinerung von FP3):
- Sentence Window Retrieval: Indem jeder Satz separat eingebettet wird und der Kontext um die relevantesten Sätze erweitert wird, stellt das System sicher, dass der bereitgestellte Kontext sowohl genau als auch ausreichend umfassend ist.
- Auto-merging Retriever: Bei dieser Technik werden granulare Informationen (Child Chunks) abgerufen und bei Bedarf automatisch zu größeren Parent Chunks zusammengeführt, um den Kontext zu erweitern, ohne die Spezifität zu verlieren.
5. Fortgeschrittenes Reranking und Filterung (Adressierung FP2):
- Fortschrittliche RAG-Systeme beinhalten ausgeklügelte Reranking- und Filtermechanismen nach dem Abruf. Dadurch wird sichergestellt, dass die endgültige Informationsmenge, die in das Sprachmodell eingespeist wird, die relevanteste ist, um die Herausforderung zu bewältigen, dass die am besten bewerteten Dokumente übersehen werden.
6. Techniken der Abfrageumwandlung (Lösung von FP6 – Falsche Spezifität):
- Bei der Umwandlung von Anfragen in fortgeschrittenen RAG-Systemen werden komplexe Anfragen zerlegt oder neu formuliert, um sie besser abrufen zu können. Dadurch wird das Problem der falschen Spezifität direkt angegangen, indem sichergestellt wird, dass die Abfragen optimal strukturiert sind, um genaue Informationen abzurufen.
7. Umfassende Antwortsynthese (Countering FP7 – Unvollständig):
- Fortgeschrittene RAG-Systeme verwenden verfeinerte Antwortsyntheseverfahren. Ob es darum geht, die Antworten iterativ zu verfeinern oder den Kontext so zusammenzufassen, dass er in die Verarbeitungsmöglichkeiten des Modells passt, diese Techniken gewährleisten umfassende und vollständige Antworten.
Durch die Integration dieser fortschrittlichen Lösungen überwinden die RAG-Systeme nicht nur die Grenzen früherer Modelle, sondern setzen auch einen neuen Standard in der KI-gesteuerten Informationsbeschaffung und -verarbeitung. Der Fokus auf die Behebung spezifischer Fehlerpunkte stellt sicher, dass diese Systeme hocheffektiv und zuverlässig sind, insbesondere in komplexen Unternehmensszenarien.
Kernkomponenten und Architektur von fortschrittlichen RAG-Systemen
Die Architektur fortschrittlicher Retrieval-Augmented Generation (RAG)-Systeme ist ein ausgeklügeltes Ensemble von Komponenten, von denen jede für bestimmte Herausforderungen und zur Verbesserung der Gesamtleistung entwickelt wurde. Hier untersuchen wir die Schlüsselkomponenten, die diese fortschrittlichen Systeme ausmachen:
")
1. Datenaufbereitung und -verwaltung:
- Integration von Metadaten und Zusammenfassungen: Fortgeschrittene RAG-Systeme nutzen Metadaten und Dokumentenzusammenfassungen, um ihren Suchindex anzureichern und die Treffergenauigkeit und Relevanz zu verbessern.
- Effizientes Chunking und Vektorisierung: Wie bereits erwähnt, setzen diese Systeme intelligentes Chunking von Dokumenten und ausgeklügelte Vektorisierungstechniken ein, um sicherzustellen, dass die in das System eingespeisten Daten optimal für das Abrufen und Verarbeiten sind.
2. Verbesserte Verarbeitung von Benutzereingaben:
- Erweitertes Abfrageverstehen: Diese Systeme verfügen über verbesserte Mechanismen zur Interpretation und Verfeinerung von Benutzeranfragen, die für Klarheit und Präzision bei der Informationsbeschaffung sorgen.
- Kontextbezogene Abfrageverarbeitung: Durch die Einbeziehung der Benutzerhistorie und des Kontexts können fortschrittliche RAG-Systeme die Antworten auf die individuellen Bedürfnisse und Vorlieben der Benutzer abstimmen.
3. Hochentwickeltes Abrufsystem:
- Hierarchische und erweiterte Indizes: Mit hierarchischen und anderen fortschrittlichen Indexierungsstrategien sorgen diese Systeme für eine effiziente und genaue Datenabfrage.
- Dynamisches Reranking und Filterung: Nach dem Abruf verfeinern fortschrittliche Reranking- und Filtermechanismen die Suchergebnisse und stellen sicher, dass die relevantesten und genauesten Informationen ausgewählt werden.
4. Erweiterte Informationsverarbeitung:
- Strategien zur Kontexterweiterung: Techniken wie Sentence Window Retrieval und Auto-merging Retriever erweitern den Kontext, der dem Sprachmodell zur Verfügung gestellt wird.
- Anfragetransformation und hypothetische Einbettung: Diese Systeme verwenden Techniken zur Umwandlung von Abfragen und hypothetische Einbettungen (HyDE), um die Abfragegenauigkeit zu verbessern.
5. Erweiterte Antwortgenerierung:
- Sprachmodelle auf dem neuesten Stand der Technik: Durch den Einsatz der neuesten Sprachmodelltechnologie generieren fortschrittliche RAG-Systeme Antworten, die kohärent, kontextbezogen und genau sind.
- Umfassende Synthesetechniken: Durch den Einsatz fortschrittlicher Synthesemethoden stellen diese Systeme sicher, dass die Antworten vollständig sind und die Anfragen der Nutzerinnen und Nutzer in ihrer Gesamtheit beantworten.
6. Kontinuierliches Lernen und Anpassen:
- Feedback-Mechanismen: Fortgeschrittene RAG-Systeme lernen kontinuierlich aus dem Feedback und den Interaktionen der Nutzer/innen und passen ihre Leistung an und verbessern sie.
- Laufende Daten- und Systemaktualisierungen: Regelmäßige Aktualisierungen der Daten und Systemkomponenten sorgen dafür, dass diese Systeme auf dem neuesten Stand der Technik und Relevanz bleiben.
7. Unternehmensintegration und Skalierbarkeit:
- Modulares und skalierbares Design: Diese auf Flexibilität ausgelegten Systeme lassen sich skalieren und an die verschiedenen Unternehmensanforderungen anpassen.
- Integration mit Unternehmenssystemen: Moderne RAG-Systeme sind so konzipiert, dass sie sich nahtlos in die bestehende Unternehmensinfrastruktur einfügen und einen reibungslosen Betrieb in verschiedenen Geschäftsumgebungen gewährleisten.
Jede dieser Komponenten spielt eine wichtige Rolle im fortschrittlichen RAG-System und arbeitet zusammen, um eine Lösung zu bieten, die nicht nur technisch überlegen, sondern auch äußerst anpassungsfähig und effizient für Unternehmensanwendungen ist. Diese Architektur schafft die Voraussetzungen für Systeme, die komplexe Abfragen mit Finesse bewältigen und Einblicke und Antworten geben können, die für Entscheidungsprozesse von großem Wert sind.
Verbesserung fortschrittlicher RAG-Systeme für den Unternehmenseinsatz

Bei der Anpassung fortschrittlicher RAG-Systeme für den Einsatz in Unternehmen muss die Kernarchitektur erweitert werden, um den spezifischen Unternehmensanforderungen gerecht zu werden. Bei diesem Ansatz werden wesentliche Funktionen integriert, die den Geschäftsanforderungen entsprechen, ohne das System mit komplexen Infrastrukturanforderungen zu überfrachten. 1. Optimierte Benutzerauthentifizierung:
- Implementiere sichere Verfahren zur Benutzerauthentifizierung. Dies ist entscheidend für die Personalisierung von Nutzererfahrungen und den Schutz sensibler Daten.
2. Robustes Input- und Output-Management:
- Entwickle Eingabeleitplanken, um schädliche oder private Daten herauszufiltern und die Systemintegrität zu gewährleisten. Ebenso sind Output-Leitplanken wichtig, um die Qualität der Antworten zu erhalten, die die Zuverlässigkeit und Vertrauenswürdigkeit des Systems widerspiegeln.
- Füge KI-gesteuerte Anonymisierung und Klassifizierung zur Benutzereingabe und Dokumentenerfassung hinzu, um die Einhaltung globaler Datenschutzbestimmungen wie GDPR zu gewährleisten.
3. Nutzer-Feedback einbeziehen:
- Die Integration von Nutzer-Feedback-Mechanismen ist für eine kontinuierliche Systemverbesserung unerlässlich. So kann das System entsprechend den Bedürfnissen der Nutzerinnen und Nutzer weiterentwickelt und das Nutzererlebnis insgesamt verbessert werden.
4. Erweiterte Abfrageverarbeitung:
- Verbessere die Fähigkeit des Systems, Nutzeranfragen zu verstehen und zu verfeinern, indem du die Historie und den Kontext der Nutzer berücksichtigst. Das führt zu genaueren und relevanteren Antworten, die das System auf spezifische Nutzeranfragen und Szenarien zuschneidet.
5. Praktische Überwachung zur Systemverbesserung:
- Richte ein Überwachungssystem ein, um die Leistung und die Interaktionen der Nutzer/innen zu verfolgen und sicherzustellen, dass das System aktuell und effektiv bleibt. Regelmäßige Aktualisierungen, um neue Daten und Verbesserungen einzubeziehen, sind entscheidend dafür, dass das System aktuell bleibt.
6. Multi-Tenancy-Fähigkeiten:
- Bereite das System so vor, dass es mehrere Benutzer oder Organisationen unterstützen kann und gleichzeitig die strikte Trennung der Daten und der Datenschutz gewahrt bleiben – eine wichtige Anforderung in Unternehmen.
Indem sie sich auf diese Verbesserungen konzentrieren, können Startups ihre fortschrittlichen RAG-Systeme effektiv für Unternehmensumgebungen anpassen. Solche Systeme verfügen nicht nur über fortschrittliche KI-Fähigkeiten, sondern sind auch pragmatisch und anpassungsfähig für Geschäftsanwendungen, so dass sie für die dynamischen Anforderungen von Unternehmenskunden gut geeignet sind.
Mit fortschrittlichen RAG-Systemen in die Zukunft blicken
Zum Abschluss unserer Untersuchung fortschrittlicher Retrieval-Augmented Generation (RAG)-Systeme stellen wir fest, dass diese innovativen Konstrukte einen bedeutenden Entwicklungsschritt in der KI-Landschaft darstellen. Fortgeschrittene RAG-Systeme sind nicht einfach nur schrittweise Verbesserungen, sondern stellen einen grundlegenden Wandel dar, der die komplexen Herausforderungen angeht, die wir zuvor untersucht haben und die in den neuesten Branchenstudien aufgedeckt wurden. Diese Systeme zeichnen sich durch eine höhere Genauigkeit, ein tieferes kontextuelles Verständnis und eine kohärente Inhaltserstellung aus. Sie verkörpern das Potenzial, die Schnittstelle zwischen KI und Unternehmensabläufen neu zu definieren, indem sie Lösungen anbieten, die genau auf die einzigartigen Anforderungen von Unternehmen zugeschnitten sind. Die Bedeutung fortschrittlicher RAG-Systeme geht über ihre technischen Fähigkeiten hinaus; sie sind ein Vorbote der transformativen Möglichkeiten, die KI für Unternehmensanwendungen bietet. Mit ihrer ausgefeilten Architektur sind diese Systeme in der Lage, die Art und Weise, wie Unternehmen KI nutzen, neu zu gestalten. Sie bieten nicht nur modernste Technologie, sondern auch Lösungen, die auf die vielfältigen Bedürfnisse von Unternehmen abgestimmt sind. Unser Dialog über fortschrittliche RAG-Systeme geht über diesen Punkt hinaus. Die kommende Fachserie wird sich mit ihren praktischen Anwendungen und den konkreten Vorteilen befassen, die sie mit sich bringen. Freue dich auf eine Reise durch die praktischen Auswirkungen dieser Systeme und das weitreichende Potenzial, das sie für die Revolutionierung der KI in Unternehmenslösungen haben. Bleib dran, wenn wir die tiefgreifenden Auswirkungen von fortschrittlichen RAG-Systemen auf die Zukunft der KI und ihre Anwendungen in Unternehmen weiter erforschen und enthüllen.



