 for enterprise")
In our previous article, we unearthed the intrinsic challenges of basic or naive Retrieval-Augmented Generation (RAG) systems, especially within the context of enterprise applications. We pinpointed issues such as retrieval difficulties due to semantic ambiguity and the lack of depth and coherence in generated responses. These insights made it clear that, despite representing a significant advancement in AI, basic RAG systems are not free from limitations. Acknowledging these challenges has paved the way for more evolved and nuanced approaches in the stages of Retrieval-Augmented Generation.
Today, we stand at the threshold of a new era in AI and information processing, where Advanced RAG Systems offer not just incremental improvements but transformative solutions. These systems demonstrate how LLMs can be effectively coupled with grounded, up-to-date, and internal data sources. This integration tailors their capabilities to meet the specific demands of enterprise applications, transitioning from the shortcomings of basic RAG systems to unveiling a sophisticated architecture that provides a contextually aware, accurate, and relevant AI solution in complex business environments.
This article begins our journey into the sophisticated architecture of Advanced RAG Systems, poised to overcome the shortcomings of their predecessors. We aim to dissect their core components and demonstrate how they adeptly manage real-world enterprise scenarios. Serving as a precursor to a comprehensive technical series, we will delve deeper into each aspect of these systems, providing practical insights for those navigating AI’s evolving landscape.
Join us in this series, where we uncover the potential of Advanced RAG Systems to revolutionize industry practices and expand the capabilities of generative AI.
The Need for Advanced Retrieval-Augmented Generation (RAG) Systems

Challenges Addressed by Basic RAG Systems
The inception of basic RAG systems was a significant stride in overcoming challenges faced by standalone generative models:
- Hallucination in Responses: These models often generated factually incorrect or ‘hallucinated’ content, lacking verification against reliable data sources.
- Limited Knowledge Base: They were constrained by the knowledge available at their last training, hindering their ability to provide current or domain-specific information.
- Costs of Training and Updating: Continually training and updating LLMs to include emerging information was resource-intensive and costly, challenging the maintenance of state-of-the-art performance.
Basic RAG systems aimed to mitigate these issues by augmenting generative models with real-time data retrieval, thus enhancing response accuracy and relevance.
Transitioning to Advanced RAG Systems for Complex Needs
Despite their innovative approach, basic RAG systems faced limitations, particularly in nuanced enterprise scenarios:
- Retrieval Issues: They struggled with accurately fetching data due to semantic ambiguity and granularity mismatch.
- Augmentation Challenges: Difficulties in integrating context and prioritizing information led to disjointed or superficial content.
- Generation Shortcomings: They often produced responses that lacked coherence, consistency, and depth, failing to meet complex business needs.
These limitations underscored the need for more sophisticated solutions. This is where advanced RAG Systems come into play, offering enhancements that are specifically designed to address these complex challenges.
Insights from a Recent Study on Failure Points of RAG Systems
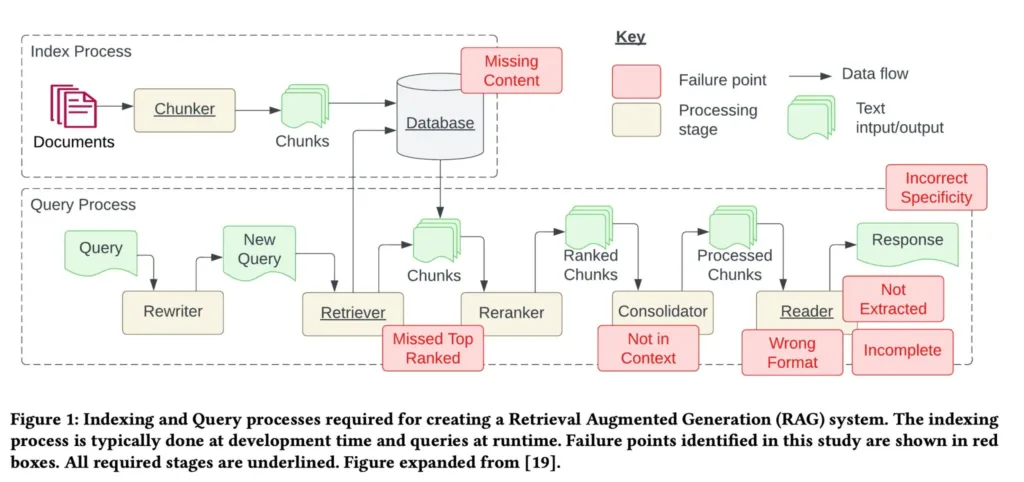
A recent study titled “Seven Failure Points When Engineering a Retrieval Augmented Generation System” seeks to further our understanding of RAG systems’ intricacies. It identifies seven key failure points, each highlighting specific areas where RAG systems can potentially fall short in delivering optimal results. These failure points are:
- Missing Content (FP1): Questions without clear answers may lead to misleading responses.
- Missed the top-ranked documents (FP2): Relevant documents may not rank highly enough to be included in user results.
- Not in context – consolidation strategy limitations (FP3): Retrieving answers is hindered when dealing with a substantial number of documents.
- Not extracted (FP4): Noise or conflicting data may lead to failure in extracting the correct information.
- Wrong format (FP5): The system may disregard specific instructions for extracting information in a particular format.
- Incorrect specificity (FP6): Responses may lack the required specificity or be overly specific.
- Incomplete (FP7): Responses may lack critical details, resulting in incomplete answers.
Bridging Insights from our Past Findings and the “Seven Failure Points”
As we progress in our exploration of advanced RAG systems, it’s vital to bridge the insights we’ve gathered from our previous discussions with the failure points identified in the recent study. This connection offers a comprehensive perspective on the challenges at hand and paves the way for the solutions provided by advanced RAG systems. Here’s how our previous insights align with the study’s identified failure points:
- Retrieval Stage:
- ‘Confusing Meanings’ and ‘Wrong Criteria Matching’ from our previous article align with Failure Points 1 (Missing Content) and 2 (Missed Top-Ranked Documents). These parallels highlight difficulties in accurate data retrieval and the relevance of responses.
- Augmentation Stage:
- Issues like ‘Context Integration’ and ‘Redundancy’ correspond to Failure Points 3 (Not in Context) and 4 (Not Extracted), emphasizing the complexities in synthesizing multi-document information and managing conflicting data.
- Generation Stage:
- ‘Coherence and Consistency’ and ‘Over-generalization’ reflect the concerns of Failure Points 1, 6 (Incorrect Specificity), and 7 (Incomplete), underscoring the need for responses that are contextually complete and specific.
By mapping these aspects, we recognize the broader patterns of challenges in information retrieval and processing. Advanced RAG systems are designed not just to address individual issues but to provide holistic solutions, enhancing the entire process of retrieval, augmentation, and generation.
Linking Past Insights to Advanced RAG Systems
The synthesis of our previous analyses and the findings from recent studies lays the groundwork for our exploration of advanced RAG systems. These systems are meticulously engineered to address specific needs:
- Enhance Data Retrieval Accuracy and Contextual Understanding: They aim to refine the precision in data retrieval and deepen the contextual grasp of the information processed.
- Improve Information Integration and Synthesis: These systems are designed to effectively merge and synthesize information from a multitude of sources, ensuring a seamless integration process.
- Offer More Coherent and Contextually-Rich Generation Capabilities: Advanced RAG systems strive to generate responses that are not only coherent but also rich in context, providing more insightful and relevant outputs.
Preview of Advanced RAG System Architecture
In the upcoming sections, we’ll dive into the architectural intricacies of advanced RAG systems. Our journey will take us through the essential components, ranging from data preparation to the intricacies of information generation. We’ll showcase how each component plays a pivotal role in crafting a robust, precise, and efficient AI tool for sophisticated enterprise applications. As we explore these elements, we’ll discover how these advanced AI solutions can be customized to meet unique business requirements, thereby opening new paths for innovation and enhancing competitive capabilities.
Advanced RAG Systems: Addressing the Shortcomings of Naive RAG

The transition from basic to advanced Retrieval-Augmented Generation (RAG) systems is a pivotal advancement in AI, specifically tailored to address the shortcomings identified in naive RAG systems. Advanced RAG architectures integrate innovative solutions, aligning closely with the needs of complex enterprise applications. Let’s explore how these advanced systems tackle the critical failure points identified in earlier models and studies:
1. Enhanced Chunking and Vectorization (Addressing FP1 – Missing Content and FP4 – Not Extracted):
- Efficient Chunking: Advanced RAG systems implement intelligent chunking, breaking down large documents into smaller, semantically meaningful units. This ensures a better representation of content, making it easier for the system to retrieve and process relevant information.
- Sophisticated Vectorization: By employing state-of-the-art embedding models, these systems enhance their ability to accurately vectorize text chunks. This leads to more precise semantic matching between queries and document content, addressing issues related to content extraction and missing information.
2. Upgraded Search Index (Tackling FP2 – Missed Top Ranked Documents and FP3 – Not in Context):
- Vector Store Index: Advanced RAG systems utilize optimized vector indices, such as faiss or annoy, enabling efficient and accurate retrieval from extensive data sets.
- Hierarchical Indices: Implementing a two-tiered indexing strategy, where summaries guide initial document selection followed by detailed chunk retrieval, ensures contextually relevant and comprehensive search results.
3. Hypothetical Questions and HyDE (Enhancing FP2 and FP3):
- Hypothetical Question Embedding: This novel approach involves generating hypothetical questions for each text chunk and embedding these for retrieval. It improves the semantic search by aligning queries closely with potential answers, enhancing the contextual relevance of retrieved documents.
- Hypothetical Document Embedding (HyDE): Similarly, these systems generate hypothetical responses based on user queries. This approach enhances the semantic match in the retrieval process, effectively addressing issues related to context relevance and missing top-ranked documents.
4. Context Enrichment Strategies (Refining FP3):
- Sentence Window Retrieval: By embedding each sentence separately and expanding the context around the most relevant sentences, the system ensures that the provided context is both accurate and sufficiently comprehensive.
- Auto-merging Retriever: This technique involves retrieving granular information (child chunks) and then automatically merging them into larger parent chunks when necessary, thereby enriching the context without losing specificity.
5. Advanced Reranking and Filtering (Addressing FP2):
- Advanced RAG systems incorporate sophisticated reranking and filtering mechanisms post-retrieval. This ensures that the final information set fed into the language model is the most relevant, addressing the challenge of overlooked top-ranked documents.
6. Query Transformation Techniques (Solving FP6 – Incorrect Specificity):
- Query transformations in advanced RAG systems involve decomposing complex queries or reformulating them for improved retrieval. This directly addresses issues of incorrect specificity by ensuring that queries are optimally structured for accurate information retrieval.
7. Comprehensive Response Synthesis (Countering FP7 – Incomplete):
- Advanced RAG systems employ refined response synthesis techniques. Whether it’s iteratively refining answers or summarizing context to fit into the model’s processing capabilities, these techniques ensure comprehensive and complete responses.
By integrating these advanced solutions, RAG systems not only overcome the limitations of earlier models but also set a new standard in AI-driven information retrieval and processing. The focus on addressing specific failure points ensures that these systems are highly effective and reliable, particularly in complex enterprise scenarios.
Core Components and Architecture of Advanced RAG Systems
The architecture of advanced Retrieval-Augmented Generation (RAG) systems is a sophisticated ensemble of components, each designed to address specific challenges and enhance overall performance. Here we explore the key components that constitute these advanced systems:

1. Data Preparation and Management:
- Metadata and Summaries Integration: Advanced RAG systems use metadata and document summaries to enrich their search index, improving the retrieval accuracy and relevance.
- Efficient Chunking and Vectorization: As discussed earlier, these systems implement intelligent chunking of documents and sophisticated vectorization techniques, ensuring that the data fed into the system is optimal for retrieval and processing.
2. Enhanced User Input Processing:
- Advanced Query Understanding: These systems feature improved mechanisms to interpret and refine user queries, ensuring clarity and precision in the information retrieval process.
- Contextual Query Processing: Incorporating user history and context, advanced RAG systems tailor responses to individual user needs and preferences.
3. Sophisticated Retrieval System:
- Hierarchical and Advanced Indices: Utilizing hierarchical and other advanced indexing strategies, these systems ensure efficient and accurate data retrieval.
- Dynamic Reranking and Filtering: Post-retrieval, advanced reranking, and filtering mechanisms refine the search results, ensuring that the most relevant and accurate information is selected.
4. Augmented Information Processing:
- Context Enrichment Strategies: Techniques like Sentence Window Retrieval and Auto-merging Retriever enrich the context provided to the language model.
- Query Transformation and Hypothetical Embeddings: These systems employ query transformation techniques and hypothetical embeddings (HyDE) to enhance retrieval accuracy.
5. Advanced Response Generation:
- State-of-the-Art Language Models: Leveraging the latest in language model technology, advanced RAG systems generate responses that are coherent, contextually rich, and accurate.
- Comprehensive Synthesis Techniques: Utilizing advanced synthesis methods, these systems ensure responses are complete and address user queries in their entirety.
6. Continuous Learning and Adaptation:
- Feedback Mechanisms: Advanced RAG systems continuously learn from user feedback and interactions, adapting and refining their performance.
- Ongoing Data and System Updates: Regular updates to data and system components ensure these systems remain at the cutting edge of technology and relevance.
7. Enterprise Integration and Scalability:
- Modular and Scalable Design: Designed for flexibility, these systems can be scaled and customized for various enterprise needs.
- Integration with Enterprise Systems: Advanced RAG systems are built to seamlessly integrate with existing enterprise infrastructure, ensuring smooth operation in diverse business environments.
Each of these components plays a vital role in the advanced RAG system, working in concert to provide a solution that is not only technically superior but also highly adaptable and efficient for enterprise applications. This architecture sets the stage for systems that can handle complex queries with finesse, offering insights and responses that are of immense value in decision-making processes.
Enhancing Advanced RAG Systems for Enterprise Application

In adapting advanced RAG systems for enterprise use, the core architecture needs augmenting to meet specific enterprise demands. This approach involves integrating essential functionalities that cater to business needs without overburdening the system with complex infrastructural requirements.
1. Streamlined User Authentication:
- Implement secure user authentication processes. This is crucial for personalizing user experiences and safeguarding sensitive data.
2. Robust Input and Output Management:
- Develop input guardrails to filter out harmful or private data, ensuring system integrity. Similarly, output guardrails are important for maintaining the quality of responses, reflecting the system’s reliability and trustworthiness.
- Add AI driven anonymization and classification to user input and document ingestion to ensure adherence to global data protection regulations like GDPR.
3. Incorporating User Feedback:
- Integrating user feedback mechanisms is essential for continuous system improvement. It allows for the refinement of the system in alignment with user needs and enhances the overall user experience.
4. Advanced Query Processing:
- Enhance the system’s ability to understand and refine user queries, drawing on user history and context. This leads to more accurate and relevant responses, tailoring the system to specific user queries and scenarios.
5. Practical Monitoring for System Improvement:
- Establish a monitoring systems to track performance and user interactions, ensuring the system remains updated and effective. Regular updates to incorporate new data and improvements are crucial for keeping the system relevant.
6. Multi-Tenancy Capabilities:
- Prepare the system to support multiple users or organizations while maintaining strict data segregation and privacy, a key requirement in enterprise settings.
By concentrating on these enhancements, startups can effectively tailor their advanced RAG systems for enterprise environments. Such systems not only boast advanced AI capabilities but are also pragmatic and adaptable for business applications, ensuring they are well-suited for the dynamic demands of enterprise clients.
Embracing the Future with Advanced RAG Systems
In wrapping up our examination of advanced Retrieval-Augmented Generation (RAG) systems, we recognize these innovative constructs as a significant evolutionary step in the AI landscape. Advanced RAG systems are not merely incremental improvements; they represent a transformative shift, addressing the intricate challenges we’ve dissected previously and those uncovered in the latest industry studies.
These systems excel in delivering heightened accuracy, deeper contextual understanding, and coherent content generation. They embody the potential to redefine the interface between AI and enterprise operations, offering solutions meticulously tailored to the unique demands of businesses.
The significance of advanced RAG systems extends beyond their technical prowess; they are a harbinger of the transformative possibilities that AI holds for enterprise applications. With their sophisticated architecture, these systems are poised to reshape the way businesses leverage AI, offering not just state-of-the-art technology but solutions fine-tuned for the multifaceted nature of enterprise needs.
Our dialogue on advanced RAG systems continues beyond this point. The forthcoming technical series will delve into their practical applications and the tangible benefits they bring to the table. As we progress, anticipate a journey through the practical implications of these systems, and the expansive potential they hold for revolutionizing AI’s role in enterprise solutions. Stay tuned as we further explore and unveil the profound impact of advanced RAG systems on the future of AI and its enterprise applications.



